走进深度学习
走进深度学习
模型构建
根据之前章节,我们已经能够发现,利用nn.Module和nn.Sequential可以很方便地构建模型,并且nn.Sequential本身也是nn.Module的一个继承类。所以,通过nn.Module来构建继承类也是非常通用的模型构建方式,一般来说,在继承类中我们会重载nn.Module的forward()函数,比如说我们可以通过继承类很容易地构建一个多层感知机模型:
forward() 函数的目的在于,定义模型的前向计算,如何根据输入的数据
x计算出所需要的模型输出y。
import torch.nn as nn
class MLP(nn.Module):
def __init__(self,**kwargs):
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256) # 隐藏层
self.act = nn.ReLU()
self.output = nn.Linear(256, 10) # 输出层
def forward(self, x):
a = self.act(self.hidden(x))
renturn self.output(a)而pytorch库会自动生成backward反向传播函数
nn.Module的子类
Pytorch提供了丰富的nn.Module子类,我们可以直接使用这些子类来构建模型,比如nn.Sequential,nn.Moudlelist,nn.ModuleDict等,这些子类都继承自nn.Module。
nn.Sequential类
nn.Sequential中,各层模型可以以多种方式输入,这一点在线性回归实现的笔记中有提到,总的来说,模型参数支持 直接输入各层、输入有序字典OrderedDict或通过add_module()函数添加。
nn.ModuleList类
该类接受一个模块列表作为输入,如:
net = nn.Modulelist([nn.Linear(256,10),nn.ReLU()])
net.append([nn.Linear(10,2)])该类的索引和列表类似,并且支持类似列表的.append()和.extend()操作。
注意
不同于nn.Sequential,nn.ModuleList类并不支持forward()函数,而是需要自己定义。但是区分于传统列表,nn.ModuleList又能够生成参数,可以通过nn.MoudleList.parameters()来访问参数,所以该类只能认为是一个模块的容器,而并不是一个新的网络。
nn.ModuleDict类
该类接受一个模块字典作为输入,也可以像字典一样操作。
和nn.ModuleList与list的关系一样,nn.ModuleDict没有定义forward()函数,需要自己定义,并且他较传统字典,他包括了模型所需要的权重参数。
- 由于三者均为
nn..Module的子类,所以可以互相嵌套调用。
不要局限了 Module 的用法
我们在softmax中定义了一个FlattenLayer层,这个层不同于一般印象里的线性计算,他只是一个reshape的操作,但是我们把这也叫做一个层。也因为如此,我们对于Module的认识应该更广泛一些,Module提供的forward函数可以看作是这个层的Action,一种广义上的行为,而不只是前向传播。
对于丢弃法 (Dropout),nn.Module也提供了nn.Dropout(drop_prob)层,以方便使用。我们需要在全连接层之后加入Dropout层,它将在训练模型中以指定的丢弃概率随机丢弃一部分神经元,而在测试模型中不发挥作用。
访问模型参数
对于用Sequential类构建的网络,我们可以简单地用net[i]调用指定层(i 的索引从 0 开始),用parameters()和name_parameters()调用参数,并且返回一个参数迭代器。
如:
net = nn.Sequential(nn.Linear(256,10),nn.ReLU(),nn.Linear(10,2))
for params in net.parameters():
print(params.size())
# 输出结果为:
torch.Size([10, 256])
torch.Size([10])
torch.Size([2, 10])
torch.Size([2])
for name,params in net.named_parameters():
print(name,params.size())
# name_parameters() 输出带有名字的参数列表,输出结果为:
0.weight torch.Size([10, 256])
0.bias torch.Size([10])
2.weight torch.Size([2, 10])
2.bias torch.Size([2])params 的对象类型
params本质上也是一个Tesnor张量,其类型为torch.nn.parameter.Parameter,可以与Tensor有同样的操作,如.data读取数据,.grad求取梯度。
初始化模型参数
一般来说,我们需要对权重赋予正态分布的初始化,对偏差清零,赋予常数的初始化,我们可以通过参数的名字对参数进行区分:
for name, param in net.named_parameters():
if "weight" in name:
init.normal_(param,mean=0,std=0.01)
if "bias" in name:
init.constant_(param,val = 0)自定义初始化方法
pytorch中对一个张量初始化是不记录梯度的,所以我们需要在with tensor.no_grad()环境里配置,比如说初始化使得整体分布于(0,0.01)的标准正态分布,但是权重有一半的概率初始化为 0,另一半参数大于 0。可以这么定义初始化函数:
def init_weight_(tensor, mean=0, std=0.01):
with tensor.no_grad():
tensor.normal_(mean,std)
tensor *= (tensor>0).float()
for name, param in net.named_parameters():
if "weight" in name:
init_weight_(param,mean=0,std=0.01)共享模型参数
只要保证两个层来自同一个数据寄存器(或者说来自同一个变量),即可保证参数共享。如:
linear = nn.Linear(10,10)
net = nn.Sequential(linear,linear)
print(id(net[0])==id(net[1]))
print(id(net[0].weight)==id(net[1].weight))
# 输出
True
True值得注意的是
在反向传播过程中,这两层的参数梯度是累加的。
自定义层
如前所说,Module这玩意是很宽泛的,可以继承它然后来构建很多自定义层。自定义层又分为两种:
- 不带模型参数的自定义层
- 带模型参数的自定义层
不带模型参数的自定义层好理解,类似
FlattenLayer就是一个不带模型参数的自定义层
本文着重讨论带模型参数的自定义层。
由前文可知,模型参数应该是Parameter类型的,也是Tensor的子类,所以我们在继承类的__init__()函数中,应该通过nn.Parameter()来定义模型参数(定义方式与Tensor一致),指定的参数名字也会被name_parameters()读取。也可以通过ParameterList()或ParameterDict()类型来定义(输入一个Parameter列表或字典),举例如下:
class MyDense(nn.Module):
def __init__(self):
super(MyDense, self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])
self.params.append(nn.Parameter(torch.randn(4, 1)))
def forward(self, x):
for i in range(len(self.params)):
x = torch.mm(x, self.params[i])
return x
net = MyDense()
print(net)Torchvision.transforms实例
torchvision.transforms提供了多种实例对数据集进行操作,多用于数据增强、图像增广。
torchvision.transforms.Resize() # 提供了重置大小转换器
torchvision.transforms.CenterCrop() # 中心裁剪
torchvision.transfotms.ToTensor() # 将数据转换为`Tensor`
torchvision.transforms.Normalize() # 将数据归一化
torchvision.transforms.RandomHorizontalFlip() # 随机水平翻转
torchvision.transforms.RandomVerticalFlip() # 随机垂直翻转
torchvision.transforms.RandomResizedCrop(200, scale=(0.1, 1), ratio=(0.5, 2))
# 随机裁剪出一块面积为原面积 10%∼100% 的区域,且该区域的宽和高之比随机取自 0.5∼2,然后再将该区域的宽和高分别缩放到 200 像素
torchvision.transforms.ColorJitter(brightness, hue, contrast, saturation)
# 改变图像颜色,参数分别是亮度、色调、对比度、饱和度
# 以上转换器可以按顺序放进列表结构中,通过`Compose`实例串联使用
torchvision.transforms.Compose(trans: list)具体应用实例可以见AlexNet模型
Pytorch 保存和加载模型
Pytorch 导入 GPU 计算
one-hot 向量的从零实现
def one_hot(x, n_class, dtype=torch.float32):
# X shape: (batch), output shape: (batch, n_class)
res = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device)
res.scatter_(1, x.view(-1, 1), 1)
return res这里最关键的是scatter_函数,官网给出的作用如下:
参数列表:
Tensor.scatter_(dim, index, src, *, reduce=None) → Tensor将张量 src 中的所有值写入索引张量中指定的索引处的 self 中。对于 src 中的每个值,其输出索引由 src 中的索引(维度!= dim)和索引中的相应值(维度 = dim)指定。
简单来说,scatter_函数的作用如下:
# for 2-D matrix
self[index[i][j]][j] = res[i][j] # if dim == 0
self[i][index[i][j]] = res[i][j] # if dim == 1我们给一个实例:
x = torch.tensor([0, 2])
one_hot(x, 5)输出:
tensor([[1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0.]])index = x.view(-1, 1) # result is [[0],[2]]
# i = 0, j = 0
index[0][0] = 0
self[0][0] = 1
# i = 1, j = 1
index[1][1] = 2
self[1][2] = 1深度学习相关概念
感受野
有关感受野可以看这篇文章
在一定的感受野下,我们愿意选择较小的卷积核,以此来获得更深的网络深度,学习更为复杂的全局特征,同时更小的卷积核意味着我们可以在较少的计算量下完成特征提取。
IOU(交并比)
Source:目标检测基础模块之 IoU 及优化 - 知乎 (zhihu.com)
IOU 其实是 Intersection over Union 的简称,也叫‘交并比’。IoU 在目标检测以及语义分割中,都有着至关重要的作用。
用该物理量表示两个图像框的相似度。 优点:
- 具有尺度不变性;
- 满足非负性;
- 满足对称性;
缺点
如果,即:两个图像没有相交时,无法比较两个图像的远近
同时无法体现两个图像是如何相交的
GIOU
它能在更广义的层面上计算 IoU,并解决刚才我们说的‘两个图像没有相交时,无法比较两个图像的距离远近’的问题。
其中,代表两个图像的最小包庇面积,也可以理解为这两个图像的最小外接矩形面积
GIoU 完善了图像重叠度的计算功能,但仍无法对图形距离以及长宽比的相似性进行很好的表示。
DIOU
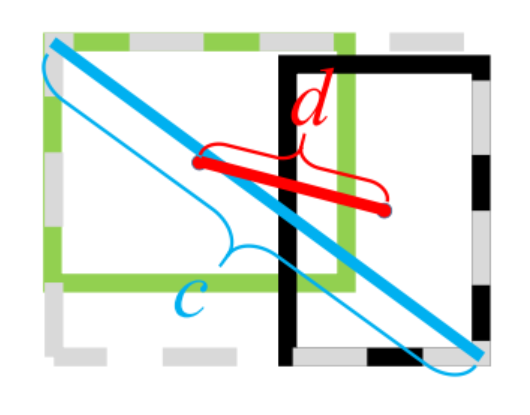
GIoU 虽然解决了 IoU 的一些问题,但是它并不能直接反映预测框与目标框之间的距离,DIoU(Distance-IoU)即可解决这个问题,它将两个框之间的重叠度、距离、尺度都考虑了进来,DIoU 的计算公式如下:
其中,,代表两个框的中心点,代表两个中心点之间的欧氏距离, 表示最小包庇矩形的对角线长
- DIoU 可直接最小化两个框之间的距离,所以作为损失函数的时候 Loss 收敛的更快;
- 在两个框完全上下排列或左右排列时,没有空白区域,此时 GIoU 几乎退化为了 IoU,但是 DIoU 仍然有效。
评价指标
混淆矩阵
混淆矩阵是一个nxn的网格,横轴表示真实值,纵轴表示预测值,每一个小方块的坐标是(真实值,预测值),即:真实值是x,但是被预测为y,如果y和x相同,也就是说在对角线上的格子,是预测符合实际的结果。
但是机器学习里为了更好地描述预测结果,给出了四个指标(TP,FP,FN,YN),很容易混淆 (因此称作混淆矩阵),现将其记录如下,并且从 0-1 预测拓展至多类预测。
0-1 预测
混淆矩阵示意图:

根据混淆矩阵定义:
A1处的数字表示:80% 的真实值为yes的数据被预测为了YesB1处的数字表示:40% 的真实值为No的数据被预测为了Yes- 其余以此类推
下面给出四个指标在 0-1 预测下的定义 (极其容易搞混,多看多记多理解)
先解释一下四个字母的由来,分别代表如下所示的单词:
| T | F | P | N |
|---|---|---|---|
| True | False | Positive | Negative |
TP:表示某对象的被预测值是Yes,并且其实际值与预测值相符,也是YesTN: 表示某对象的被预测值是No,并且其实际值与预测值相符,也是NoFP: 表示某对象的被预测值是Yes,但是其实际值与预测值相悖,是NoFN: 表示某对象的被预测值是No,但是其实际值与预测值相悖,是Yes
故这四个指标的分布应该如下所示(横轴真实值,纵轴预测值):
| Yes | No | |
|---|---|---|
| Yes | TP | FP |
| No | FN | TN |
理解
对 P、N 的理解
P、N 表示的是预测值的正/负,但具体是哪个标签叫做正,哪个标签叫做负,是由人来决定的,我们这里默认预测为Yes时,预测值是Positive的。
你当然可以说我要的是
No标签,那此时预测出No就得用P表示(也从此我们可以引出多种类别的预测)
对 T、F 的理解
T、F 表示的是实际值与预测值是否相反。如果是T,说明实际值与预测值相同;如果是F,说明实际值与预测值相反。
这也是为什么我要先写
对P、N的理解再来写对T、F的理解,因为我们是先看的后边字母,再看的前边字母,才能得到这个指标对应的预测值和实际值都是什么标签。
多类预测
结合 0-1 预测的概念,我们可以将这四个极易混淆的指标推导到多类预测的情况下,多类预测的混淆矩阵是一个的矩阵,如图所示。

与 0-1 预测类似,多类预测里的P与N是针对某一个标签而言的,比如说上图种我需要的是Crack类别,那预测值为Crack就是Positive的,预测值不是Crack的统统归为Negative,因此可以得到多类预测下四个指标的解释:
TP:表示某对象的被预测值是Crack,并且其实际值与预测值相符,也是CrackTN: 表示某对象的被预测值不是Crack,并且其实际值与预测值相符,也不是CrackFP: 表示某对象的被预测值是Crack,但是其实际值与预测值相悖,不是CrackFN: 表示某对象的被预测值不是Crack,但是其实际值与预测值相悖,是Crack
召回率与准确率
因此可以得到召回率与准确率的定义:
- 召回率
召回率描述的是实际值为Yes的标签中有多少被正确预测了。
- 准确率
准确率描述的是预测出Yes的标签中,有哪些是和实际值相符的。
Confidence 与 IOU 阈值
二者虽然类似,但是有很大的差别。
- Confidence是基于预测框的预测值来定义的,confidence定义了大于多少置信度的预测框才会被认为是有效的。比如说某个物体,AI 模型认为他有 0.5 的概率是 X(即:预测框的置信度是 0.5),若此时confidence调成 0.4,则该框会输出在最终图上,若此时confidence设置成 0.6,则该框不会输出在最终图上。
最佳的confidence应该从输出结果图中F1-confidence曲线来判断,取F1为最高点时对应的confidence即可,千万不要根据测试集去改confidence,我们因为这点在中南自院计算机视觉比赛中吃了大亏。
- IOU_conf 是用来抑制多余框的,如果IOU_conf=1,此时输出图中会有非常非常多重合的框,因为此时 AI 认为,只有当两个框完全重合(即:此时两个框的 IOU 为 1)时,才可以认为这是同一个框,才可以去除其中一个。而例如,当IOU_conf=0.8时,系统认为两个框要重合到 >0.8 时,才可以认为这是同一个框。